Works
收录典型成果,更多内容见 resume。
论文#
2026
ST4VLA: Spatially Guided Training for Vision-Language-Action Models
提出 Spatially Guided Training,将 spatial grounding pre-training 与 spatially guided action post-training 串联起来,在 SimplerEnv 上取得显著提升。
InternVLA-A1: Unifying Understanding, Generation and Action for Robotic Manipulation
统一 understanding、generation 与 action 的机器人操作模型,以 Mixture-of-Transformers 协同 scene understanding、visual foresight 和 action execution。
2025
InternVLA-M1: A Spatially Guided Vision-Language-Action Framework for Generalist Robot Policy
将空间 grounding 与机器人控制统一到同一框架,通过两阶段 spatially guided 训练提升 instruction following、泛化与长任务鲁棒性。
产品项目#

交警场景大模型
量产 / 大模型 / 展车落地面向自动驾驶复杂场景中的交警指挥理解,推动公司内部首次 VLM 在自动驾驶场景实现量产级上线,并完成展车部署落地。该任务兼具高场景价值、高理解难度与强用户感知,是少数能够真正拉开智能化体验差距的复杂能力。
出彩点
- 实现公司内部首次 VLM 在自动驾驶场景的量产级上线,并形成展车可演示成果
- 在交警指挥关键任务中,将模型 precision 从 GPT-4o 基线约 30% 提升至 95%+
- 展示效果获得媒体自发传播与正向反馈,成为对外认知度很高的差异化亮点
我的职责

Vision Pro 手眼交互
人手重建 / XR 交互 / 展示项目围绕 Apple Vision Pro 手眼交互能力打造车载展示与实车方案,在高复杂度、多模块强耦合约束下完成车载 15.6 寸屏首发落地,并进一步推进到多应用实车验证。整体交互精度、稳定性与展示效果达到领域首次、领域领先水平。
出彩点
- 完成车载 15.6 寸屏 Vision Pro 手眼交互首发落地及量产级 Demo 验证
- 牵头 15 名核心开发并协同 43 人跨团队推进,按车展节点完成高质量交付
- 空间手势重建与视线协同交互效果显著优于同期方案,并获得客户正向反馈
我的职责

指向地图 / 看哪问哪
多模态交互 / 实车展示 / 地图理解面向车载场景打造“看哪问哪 / 指哪问哪”的人-车-环境联合交互方案,完成业内首次单目 3D 手势交互 Demo,实现从 0 到 1 的实车验证。项目贯通座舱与自动驾驶信息流,是舱驾一体多模态交互方向的代表性成果。
出彩点
- 完成业内首次单目 3D 手势上车 Demo,首次打通“人-车-环境”联合交互能力
- 吸引 10+ 主机厂及同行现场观摩与拍摄,具备很强展示性与传播性
- 理想等客户多轮实车体验,并将相关能力纳入自身 Demo 体系与后续规划
我的职责
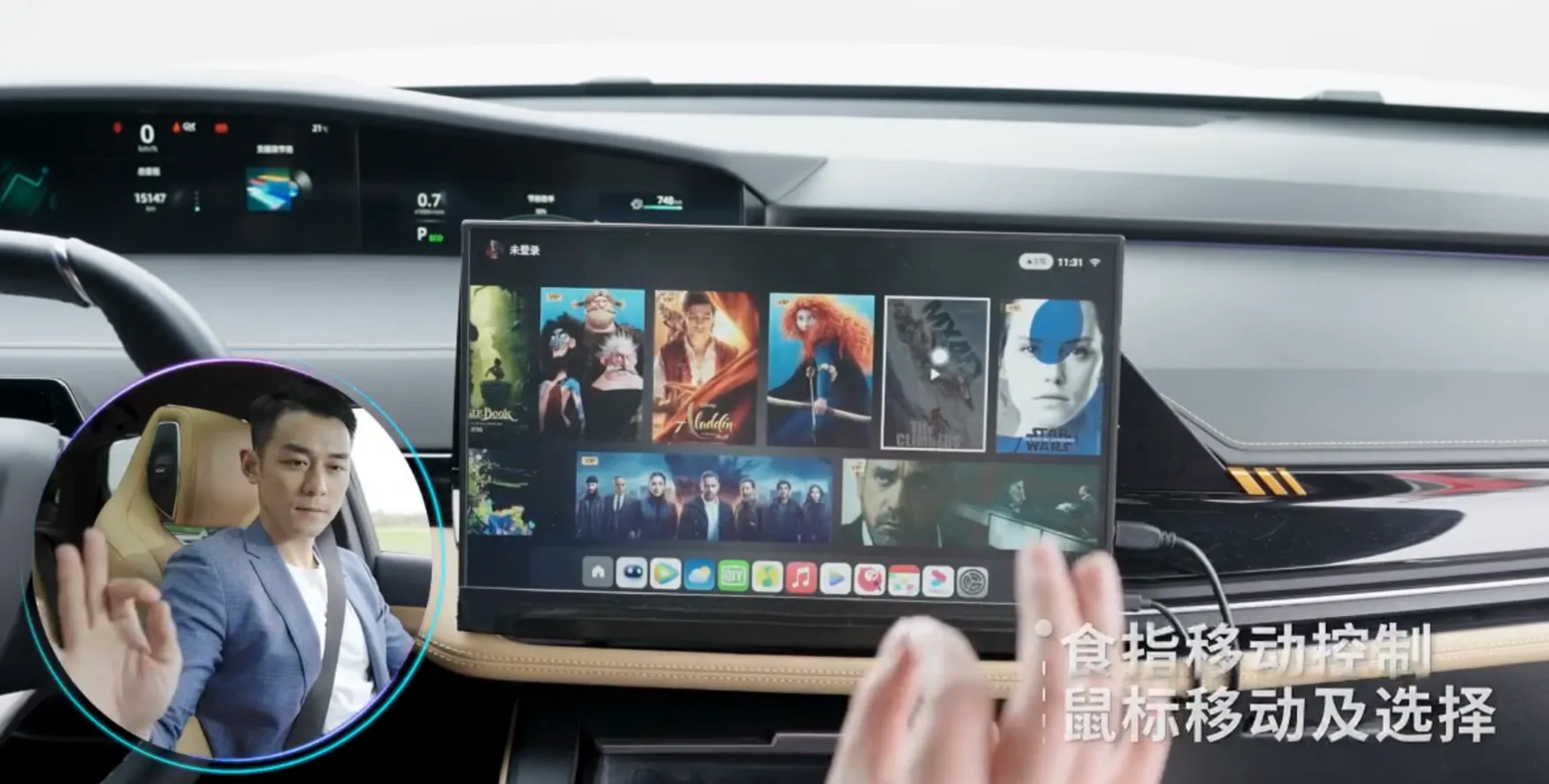
TOF 遥控
3D 交互 / POC / 客户交付围绕 TOF 遥控器一期与广汽 POC TOF 两个阶段展开,目标是打造可量产演进的真 3D 控屏能力,并将方案从技术验证推进到客户可感知、可交付的量产级 POC。项目重点解决传统控屏方案易疲劳、稳定性不足和交互维度受限的问题。
出彩点
- 打造真 3D TOF 控屏能力,并完成面向客户的量产导向 POC 验证
- 设计“捏合 + 指向”双范式控屏交互,有效降低手势疲劳感并提升稳定性
- Demo 体验优于市面方案并获得客户高度认可,形成从架构到 SDK 再到对外交付的完整闭环
我的职责

车载人手重建 GT 系统
数据基建 / GT 系统 / 人手重建面向车载人手重建建设长期数据基建,围绕 GT 系统打通采集、标注、验证与算法迭代底座,为 TOF、单目、多目等多条技术路线提供统一高质量数据支撑。这类项目不直接面向用户,但决定了后续能力上限与迭代效率。
出彩点
- 从 0 到 1 搭建车载人手数据采集与标注体系,沉淀长期可复用的数据底座
- 基于 MANO 与多视角几何约束构建异构多目 4D GT 自动生成能力,显著降低 3D 数据获取成本
- 支撑 TOF、单目、多目多路线并行迭代,是后续空间交互能力演进的关键基础设施
我的职责
开源项目#
InternVLA-M1
具身智能 / VLA / 开源面向通用机器人策略的 Vision-Language-Action 开源框架,强调 spatially guided、dual-system 和 dual-supervision 训练范式,将语言理解、空间感知与动作预测统一到同一套框架中。我主要负责 Sys2 pretrain,以及长任务拆解能力相关设计与落地。后续进一步延伸到 StarVLA,形成更模块化、可扩展的 VLA 开发生态。
Quest_Tele
VR / 遥操作 / 机器人工具 / 开源基于 Meta Quest 3 的 VR 双手位姿采集与机器人遥操作工具,支持手柄模式与人手追踪模式,通过局域网 HTTP / JSON 实时发送头显、手腕、手柄和 24 关节数据,并提供 Python 侧接收与可视化监控脚本,便于快速接入遥操作与采集流程。